Or Maybe It Is, Depending on What You’re Thinking
I spent the last few weeks combining my Obsidian graph with GPT vector embeddings, creating a fully personal, fully local, fully operable Google for my personal notes.
And it got me thinking.

a embeddings vector query and its result. say cheese!
What *is* search?
Why do we search for things in the first place?
Is search a shortcut to truth?
Is search a pathway to satiate our bottomless desire as a species for information?
Perhaps it’s a way to feel connected, to come to terms with unanswered questions, to commune with the Oracle of time and space.

Whatever search is, we all do it. A lot.
Google has been visited 62.19 billion times this year. (yes, I googled that, so 62.19 billion + 1) [^1]
People have questions, and the Internet has answers. Or does it?
We Ourselves are Producers of Data
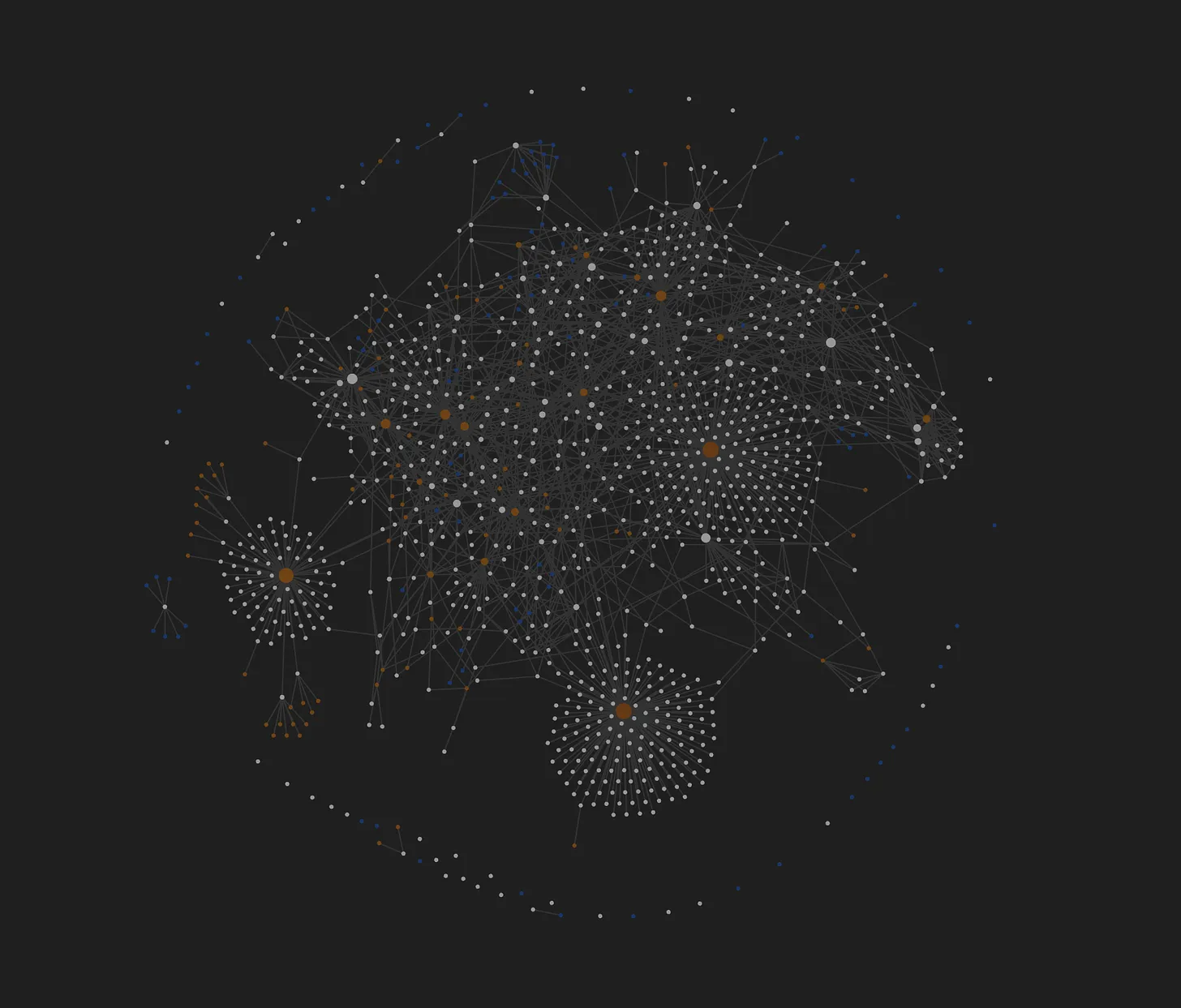
my obsidian graph
We all are active producers of data, even when we consume data.
There is no such thing as an independent observer. By interacting with the web, you become the web.
The picture above illustrates my personal web of information, my Zettelkasten.[^2]
My Zettelkasten is a collection of my ideas, thoughts, concerns, opinions, preferences, revelations, conflicts, experiences, and many many more.

If you’ll notice, everything is connected to everything else. Sure, some nodes get visited infrequently like a rural town buried in the mountains, some nodes drift along doing their own thing like a digital nomad living out of her suitcase. But all of the nodes are purposeful and have some relationship with the overall graph.
Where Does Our Data Go?
For many, data is consumed and then lost to the flow of time in favor of the final experience. The wood shavings are scattered across the workshop floor, waiting to be swept into the proverbial trash can.
But data is flexible.
Data can be re-contextualized, reshaped at will. Data can, in a sense, revive itself from “death”.

Data can have a brand new life when it is merely examined from a different angle.
If we are willing to store our experiences on the web in storage systems we trust, that data does not need to be transient. It does not need to be subsumed by the environment it is a part of.
It can be assimilated.
And that’s where embeddings comes in.
Embeddings and Stuff
The main workflow of Google is to:
- index data
- store the data
- return relevant data on query
With Embeddings [^3], we can do the same thing, at a fraction of the financial cost and a fraction of the data lock in.
Let’s break down each step.
The Right Stuff

Not all data is useful. In fact, most data is noise outside of the specific context in which it was made.
The first step to getting valuable data is to chunk.
Chunkin’
To chunk data, we are merely splitting it into useful fractions.
For this blog post, a good chunk candidate would be line breaks. For a video, it could be jump cuts.

Whatever it is, it must be atomic enough to be standalone, yet large enough to hold enough relevant information.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
We then embed each chunk, turning text into a 2D Vector representation.

Store It in a U-Haul!
Next, we need a place to put all these chunks. A database seems like a reasonable option.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Query It Like Beckham
Finally, we use cosine similarity [^4] (a pretty cool function if I do say so myself) to query all this new data we created.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Wrapping Up
The search of tomorrow involves data captured today. Pay attention to the trail your data leaves behind, and ask yourself, could this have another life?

ars longa, vita brevis
Bram